C++六种内存序详解

前言
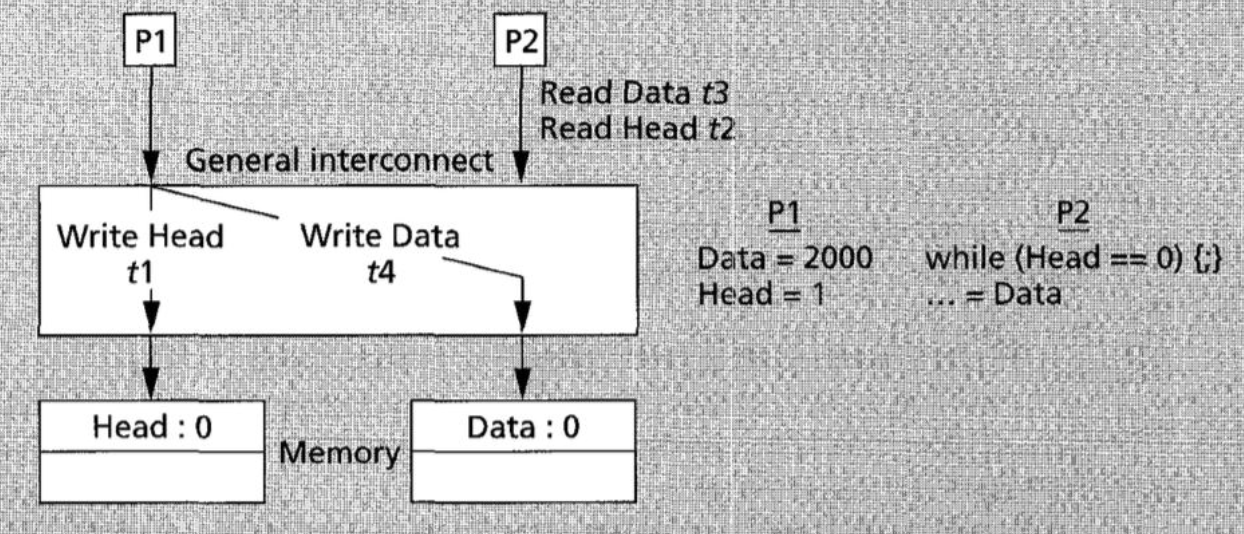
- P1 先完成了 Data 在内存上的写操作, Data=2000;
- P1 没有等待 Data 的写结果传播到 P2 的缓存中,继续进行 Head 的写操作, Head=1;
- P2 读取到了内存中 Head 的新值;
- P2 继续执行,读到了缓存中 Data 的旧值, Data=0。
在讲六种内存序之前,先明白两种关系
Happens-before
happens-before 关系是一种逻辑关系,它确保内存操作的有序性和可见性。如果在程序中操作A happens-before操作B,那么操作A的效果(包括对内存的修改)保证对启动操作B的线程可见,并且A的执行在时间上先于B。
Synchronizes-with
synchronizes-with 是C++内存模型中的一个特定类型的 happens-before 关系,它主要用于描述同步机制(如互斥锁、原子操作等)。这种关系指明了程序中的两个操作之间通过某种同步机制直接建立的顺序关系。如果操作A synchronizes-with操作B,则A happens-before B。
例如:
- 一个线程释放(unlock)一个互斥锁,然后另一个线程获取(lock)这个互斥锁,释放操作与获取操作之间存在
synchronizes-with关系。 - 对原子变量执行
store操作(使用memory_order_release或更强的顺序)与另一个线程上对该原子变量进行load操作(使用memory_order_acquire或更强的顺序)之间也存在synchronizes-with关系。
memory_order_relaxed
唯一的要求是在同一线程中,对同一原子变量的访问不可以被重排,不同的原子变量的操作顺序是可以重排的。它不提供任何跨线程的内存顺序保证。
1 int x = 0; 2 int y = 0; 3 // Thread 1: 4 r1 = y.load(std::memory_order_relaxed); // A 5 x.store(r1, std::memory_order_relaxed); // B 6 // Thread 2: 7 r2 = x.load(std::memory_order_relaxed); // C 8 y.store(42, std::memory_order_relaxed); // D
代码执行后,y1=y2=42的情况是可能出现的,因为第8行的代码可以被重排到第7行之前执行。
memory_order_release & memory_order_acquire & memory_order_consume
Acquire-Release能保证不同线程之间的Synchronizes-With关系,这同时也约束到同一个线程中前后语句的执行顺序。release语句之前的所有变量的读写操作(including non-atomic and relaxed atomic)都对另一个线程中的acquire之后的代码可见。
1 #include <atomic> 2 #include <thread> 3 #include <assert.h> 4 5 std::atomic<bool> x,y; 6 std::atomic<int> z; 7 8 void write_x_then_y() 9 { 10 x.store(true,std::memory_order_relaxed);// 1 11 y.store(true,std::memory_order_release);// 2 12 } 13 14 void read_y_then_x() 15 { 16 while(!y.load(std::memory_order_acquire));// 3 17 if(x.load(std::memory_order_relaxed)) //4 18 ++z; 19 } 20 21 int main() 22 { 23 x=false; 24 y=false; 25 z=0; 26 std::thread a(write_x_then_y); 27 std::thread b(read_y_then_x); 28 a.join(); 29 b.join(); 30 assert(z.load()!=0); 31 }
代码执行后assert永远为true. 代码中1一定发生在2之前(happens-before), 2一定发生在3之前(Synchronizes-With), 3一定发生在4之前(happens-before);
而Release-Consume只约束有明确的carry-a-dependency关系的语句的执行顺序,同一个线程中的其他语句的执行先后顺序并不受这个内存模型的影响。release语句之前的有依赖关系的变量的读写操作都对另一个线程中的consume之后的代码可见。
上面的代码的第16行如果从std::memory_order_acquire改成std::memory_order_consume, 最后z是有可能为0的,因为变量x和y之间不存在依赖关系,thread b不一定能看到thread a中的对x的写操作。
根据cppreference,目前memory_order_consume是不建议使用的。

memory_order_acq_rel
它结合了memory_order_acquire 和 memory_order_release 的特性,确保了本线程原子操作的读取时能看到其他线程的写入(acquire 语义),并且本线程的写入对其他线程可见(release 语义),主要用于read-modify-write操作,如fetch_sub/add或compare_exchange_strong/weak。
1 #include <atomic> 2 #include <iostream> 3 #include <thread> 4 5 struct Node { 6 int data; 7 Node* next; 8 }; 9 10 std::atomic<Node*> head{nullptr}; 11 12 void append(int value) { 13 Node* new_node = new Node{value, nullptr}; 14 15 // 使用 memory_order_acq_rel 来确保对 head 的修改对其他线程可见, 同时确保看到其他线程对 head 的修改 16 Node* old_head = head.exchange(new_node, std::memory_order_acq_rel); 17 18 new_node->next = old_head; 19 } 20 21 void print_list() { 22 Node* current = head.load(std::memory_order_acquire); 23 while (current != nullptr) { 24 std::cout << current->data << " "; 25 current = current->next; 26 } 27 std::cout << std::endl; 28 } 29 30 void thread_func() { 31 for (int i = 0; i < 10; ++i) { 32 append(i); 33 } 34 } 35 36 int main() { 37 std::thread t1(thread_func); 38 std::thread t2(thread_func); 39 40 t1.join(); 41 t2.join(); 42 43 print_list(); 44 45 return 0; 46 }
memory_order_seq_cst
它满足memory_order_acq_rel的所有特性,除此之外,它强制受影响的内存访问传播到每个CPU核心。它不仅保证了单个原子变量操作的全局顺序,而且保证了所有使用顺序一致性内存序的原子变量之间的操作顺序在所有线程的观测中是一致的。
我们先看一个例子
1 #include <atomic> 2 #include <cassert> 3 #include <thread> 4 5 std::atomic<bool> x = {false}; 6 std::atomic<bool> y = {false}; 7 std::atomic<int> z = {0}; 8 9 void write_x() 10 { 11 x.store(true, std::memory_order_release); 12 } 13 14 void write_y() 15 { 16 y.store(true, std::memory_order_release); 17 } 18 19 void read_x_then_y() 20 { 21 while (!x.load(std::memory_order_acquire)) 22 ; 23 if (y.load(std::memory_order_acquire)) 24 ++z; 25 } 26 27 void read_y_then_x() 28 { 29 while (!y.load(std::memory_order_acquire)) 30 ; 31 if (x.load(std::memory_order_acquire)) 32 ++z; 33 } 34 35 int main() 36 { 37 std::thread a(write_x); 38 std::thread b(write_y); 39 std::thread c(read_x_then_y); 40 std::thread d(read_y_then_x); 41 a.join(); b.join(); c.join(); d.join(); 42 assert(z.load() != 0); 43 }
运行代码,最后是可能出现z=0的情况的
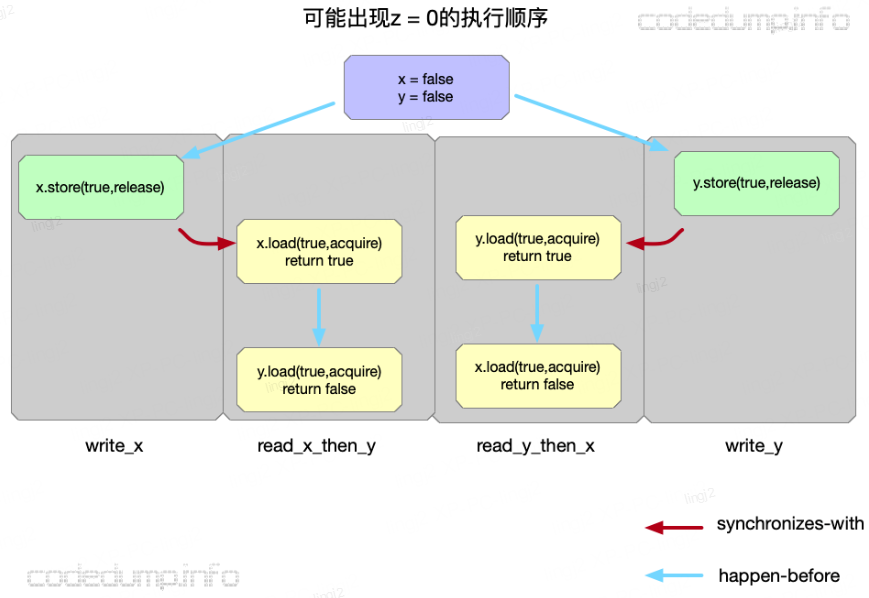
原因是read_x_then_y和read_y_then_x看到的x和y的修改顺序并不一致,也就是说read_x_then_y看到的是先修改了x再修改y, 而read_y_then_x看到的是先修改y再修改x, 这种现象出现的原因仍然可以归结到写操作的传播上,在某一时刻write_x的修改只传播到了read_x_then_y线程所在的processor,还没有传播到read_y_then_x线程所在的processor, 而write_y的修改只传播到了read_y_then_x线程所在的processor,还没有传播到read_x_then_y线程所在的processor.
如果我们要保证最后z一定不等于0,需要将代码中std::memory_order_acquire和std::memory_order_release都换成std::memory_order_seq_cst, 这样才能保证read_y_then_x和read_x_then_y观察到的对x和y的修改顺序是一致的。
参考文档
https://en.cppreference.com/w/cpp/atomic/memory_order
https://www.codedump.info/post/20191214-cxx11-memory-model-1/
https://www.codedump.info/post/20191214-cxx11-memory-model-2/
https://www.zhihu.com/question/24301047/answer/83422523
原文地址:https://www.cnblogs.com/ljmiao/p/18145946